.png)
1. Introduction
Large Physics Models (LPMs) have the potential for tremendous impact in engineering: by learning from large volumes of simulation data, they promise to cut data requirements and training costs while enabling fast design exploration and optimization. But in external automotive aerodynamics, we’ve found that today’s most widely used public datasets (DrivAerNet++ and Luminary SHIFT-SUV) don’t contain enough geometric diversity to support truly general models — or realistic benchmarks — because most “good” results come from in-distribution evaluation that doesn’t match how industry actually uses these tools.
In this post, we introduce our approach to building LPMs in practice. We built a high-throughput, industrial-grade simulation pipeline — the PhysicsX Data Factory — to create PXNetCar, a proprietary dataset of 20K+ CFD simulations spanning 250+ distinct baseline vehicle designs, specifically designed to cover the real design space and enable out-of-distribution (OOD) evaluation on novel vehicles. Using PXNetCar alongside public datasets, we show that state-of-the-art architectures still generalize poorly to OOD design and cross-simulator settings, and we quantify two critical axes of generalization: across new geometries and across CFD setups. We then establish an empirical data scaling law showing that OOD performance improves steadily with more diverse training data, and demonstrate that training on multiple datasets/simulators can recover in-simulator performance — suggesting a path toward models that assimilate heterogeneous simulation sources without sacrificing accuracy.
These results motivate scaling dataset diversity and simulator coverage in automotive aerodynamics — and applying the same pattern to other domains — so we can deliver pre-trained physics AI that customers can adapt into private, continuously improving LPMs and deploy directly into optimization and inverse-design workflows on the PhysicsX platform.
1.1 From Neural Surrogates to Large Physics Models
Neural surrogates are typically trained on narrow datasets, which limits generalization. LPMs represent a new class of models that aim to overcome this by scaling data and model size to enable generalization across inputs, tasks, and physics domains. At their core, LPMs are trained on large volumes of labeled data from numerical simulators and physical experiments. In addition to physics-based data, they may also incorporate text, images, video, and geometric information.
However, generating such data is expensive, as it depends on either computationally intensive simulations or costly physical experiments. The importance of dataset curation in science and engineering has now reached the level of governmental recognition. In the United States, the GENESIS mission has been launched to advance AI for science, with similar initiatives emerging in the European Union. Recent work has also established theoretical scaling laws specific to modeling computational fluid dynamics (CFD) simulation data (Ashton et al., 2025), highlighting both the opportunity and the computational economics involved.
PhysicsX’s core strength lies in our close collaboration and co-engineering with customers across multiple industrial domains, enabling rapid feedback on the practical utility of LPMs and insights into how they are best deployed. Our approach to LPM development centers on fast iteration through a vertical-first strategy: we establish strong baselines on single-physics, single-task problems, while curating high-quality datasets from simulators, experiments, and synthetic sources. As this pattern matures, we plan to expand toward cross-vertical models and broader physics foundation models.
1.2 Automotive Aerodynamics: Motivation and Modeling Context
We chose automotive aerodynamics as our first LPM vertical because numerical simulation sits at the heart of the domain, and engineering teams are highly sophisticated in how they use CFD. Automotive manufacturers place strong emphasis on efficiency and innovation, which creates a pressing need for rapid design iteration. Drawing on our automotive engineering experience, from the Formula 1 background of our co-founders and colleagues to our work with multiple original equipment manufacturers (OEMs), we developed an AI surrogate pre-trained on CFD simulations and deployed it through the PhysicsX platform.
The Navier–Stokes (NS) equations govern the physics of classical Newtonian fluids, but their numerical solution has evolved into a complex ecosystem of mathematical formulations, numerical algorithms, and industrial simulation software. Simplification strategies to make the equations computationally tractable exist (e.g., Reynolds-Averaged NS (RANS) with turbulence closure models), but simulations still carry significant cost, limiting engineering iteration cycles for design exploration and optimization.
At its core, the modeling challenge is to learn the mapping from vehicle geometry, inlet velocity, and other boundary conditions and parameters of the NS equations (inputs) to surface fields such as pressure and wall shear stress, and volumetric fields including velocity and pressure that satisfy the governing equations (outputs). From the output fields, we derive the key performance metrics that define design success: integrated forces such as drag, lift, and side force. Among these, drag reduction remains a primary indicator of improved aerodynamic performance in many industry use cases.
In reality, a fidelity gap separates the idealized NS equations from real-world behavior, which is bridged by CFD simulators, wind tunnel experiments, and real-world testing. Since CFD data is the most abundant and controllable of these, we focus our modeling efforts there. However, CFD is not monolithic: the choice of simulator (RANS, Detached Eddy Simulation (DES), Large Eddy Simulation (LES), Direct Numerical Simulation (DNS)), turbulence closure model (e.g., Spalart-Allmaras, k–epsilon or k–omega), boundary conditions, mesh resolution, and further algorithmic details all meaningfully influence the results. This means that simulator variation is a critical and largely overlooked factor in creating training data for physics AI applications. We discuss this later in this post and outline potential approaches to mitigate its impact.
1.3 The Diversity and Benchmarking Gap in Publicly Available Datasets and Studies
Developing LPMs requires access to large volumes of data that span a broad range of physical scenarios. In automotive aerodynamics, there are several prominent datasets, including DrivAerNet++ (8,121 geometries across three baselines, Elrefaie et al., 2024) and Luminary SHIFT-SUV (1,994 geometries across two baselines, Luminary 2025). These have been fundamental for advancing models that operate on or around complex vehicle surfaces; for example, DrivAerNet++ includes detailed underbody and rim geometry. However, the design spaces they cover are derived from a very limited number of base geometries, with most variation introduced through extensive parametric morphing. We illustrate this below in Figure 1.
This limited diversity has direct consequences for benchmarking. When evaluating models using standard random train/test splits utilized in other studies, we observe strong test-set performance. However, this is largely because random splits allow morphs of the same baseline to appear in both training and test sets. Since these morphs are highly similar, the resulting evaluation is effectively in-distribution. A true LPM for automotive aerodynamics must generalize to whatever car design a customer brings to it, not just small morphs of a design it was trained on. Standard random splits do not test for this.
Out-of-distribution evaluation is gaining recognition as an important task (Elrefaie et al., 2025), but the limited diversity of existing datasets constrains it: when the underlying design space is narrow, held-out test sets cannot be truly distinct from the training data. We investigate this in Sections 3.1 and 3.2, where we evaluate models under both in-distribution and out-of-distribution conditions across datasets of varying diversity.
Taken together, these observations indicate that both the diversity of existing datasets and the evaluation standards commonly accepted in the literature are insufficient for real-world industrial applications, which require zero- or few-shot generalization to entirely new designs. This motivated the development of the PhysicsX Data Factory, designed to generate diverse, validated simulations at scale (see Section 2.1). Beyond design diversity, generalization across simulators poses a distinct challenge. In this post, we present zero-shot cross-simulator results that quantify the problem (see Section 3.3). Adaptation strategies, such as fine-tuning on target simulator data and other techniques, are underway and will be presented in future work.
2. Towards Large Physics Models
We now describe our approach to the challenges identified above. We introduce the PhysicsX Data Factory and PXNetCar — a growing dataset designed to address the design diversity gap — and outline the model architecture and training strategy.
2.1 The PhysicsX Data Factory
To bridge the gap between academic benchmarks and engineering reality, we built an industrial-grade pipeline for generating high-quality training data at scale. We recognize multiple strata in the data distribution that are factors of diversity, as outlined in the recent Fluid Intelligence paper (Ashton et al., 2025), including vehicle design, boundary conditions, simulator, and simulation fidelity. These drivers of diversity represent the dimensions along which we evaluate model generalization, as each captures a distinct aspect of the model’s practical utility.
With this pipeline, we created PXNetCar, a dataset that initially targets geometric variability with a fixed simulator configuration (RANS, described below). However, because DrivAerNet++ and Luminary SHIFT-SUV each use different simulators, combining them with PXNetCar provides an opportunity to explore multi-simulator training, which we evaluate in Section 3.4.
To generate a geometrically diverse dataset, we obtained 260 baseline geometries representing distinct vehicle designs across a range of car types (Figure 1). These are high-fidelity car models (e.g., mean vertex count ~750K) sourced from large-scale 3D model libraries and rigorously filtered for geometric detail and surface quality, ensuring they capture the aerodynamically relevant features found in production vehicle designs. From each baseline, our engineers define a set of shape modifications targeting regions known to significantly influence aerodynamic performance, for example, the front-end curvature, roofline profile, underbody geometry, rear diffuser angle, and wake-forming surfaces. We then combine these modifications using Latin hypercube sampling to efficiently span the design space, generating approximately 100 meaningful variants per baseline. The Data Factory simulates hundreds of such diverse baseline vehicles, with the dataset growing daily. This yields a rich and continually expanding training dataset, which at the time of writing comprises 20,486 geometries and associated RANS simulations. We are continuously broadening this dataset by adding new engineering use cases and physical domains.
The Data Factory is built around three core pillars:
- Throughput: The Data Factory operates continuously, running Simcenter STAR-CCM+ to generate hundreds of CFD simulations per day. The system runs autonomously, loading new geometry variants into a predefined workflow that automatically generates meshes, executes CFD simulations, and extracts relevant data ready for consumption by the model. The simulations employ the RANS k-omega SST turbulence model, which provides a good balance between the accuracy needed for common engineering design use cases and computational efficiency. All simulations use a fixed inlet velocity of 30 m/s. Varying the inlet velocity is a natural next step we plan to explore in future work. We are also investigating expansion to other simulation methods, such as DES, including transient models.
- Geometric diversity and fidelity: We generate CFD-ready meshes that capture the complexity and nuance of real-world automotive geometries rather than simplified shapes. Vehicle geometries are sourced from public repositories, manually inspected and repaired to address issues such as non-watertightness and self-intersections, and then morphed using Blender to create variants. We maintain focus on industry-relevant geometries that represent diverse automotive shapes and design approaches.
- Rigorous validation: Every simulation is subject to a comprehensive set of validation checks, including solver convergence and physical field bounds — for example, ensuring that the pressure coefficient does not exceed 1.0, which would be unphysical. Similar validation is applied at each post-simulation processing stage, such as surface decimation, to ensure that all data transformations remain realistic and faithful to the underlying simulation output. This quality assurance process is essential: to train a model that generalizes, the underlying physics must be unimpeachable. Full automation of these validation checks enables high simulation throughput without compromising data quality.
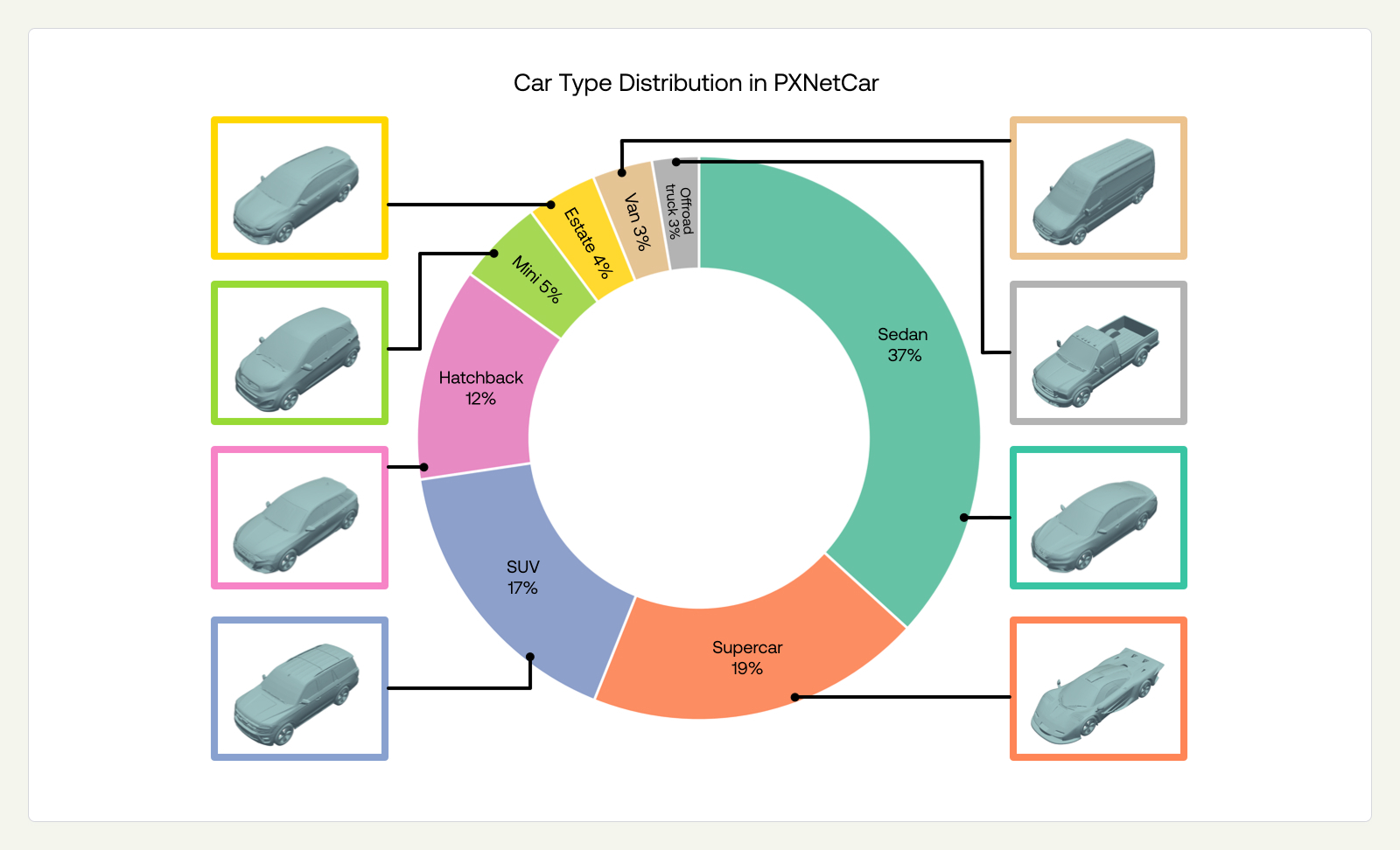
2.2 PXNetCar Is More Diverse than Public Datasets
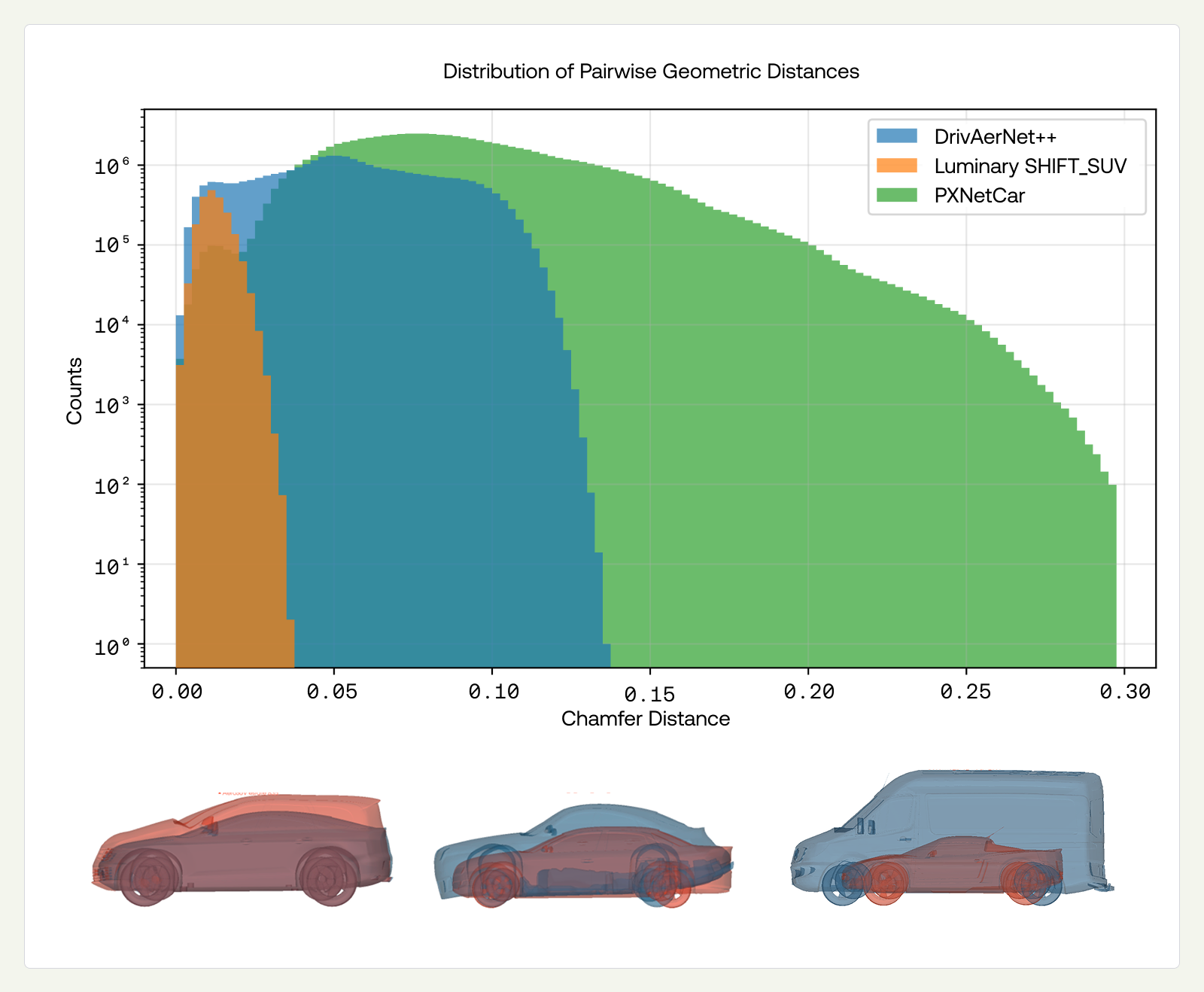
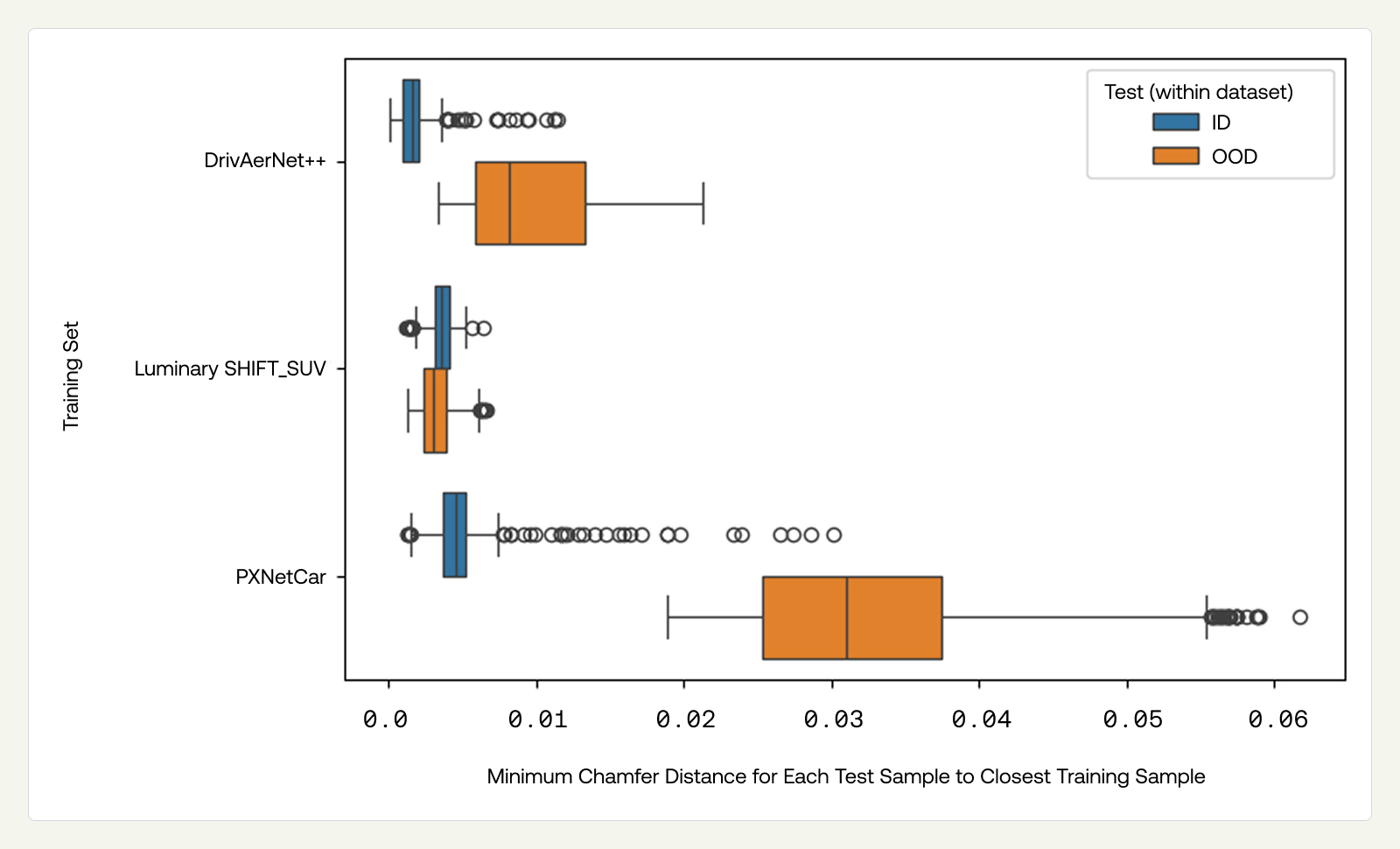
To illustrate the diversity of PXNetCar, we computed the pairwise chamfer distance (point to mesh after aligning) between vehicles within each dataset independently — DrivAerNet++, Luminary Shift-SUV, and PXNetCar — and used it as a proxy for meaningful diversity. Examining the histograms of distances in Figure 2, we observe that vehicles within DrivAerNet++ and Luminary Shift-SUV have more similarities compared to PXNetCar. The extended tail of PXNetCar demonstrates coverage of fundamentally distinct vehicle classes, from compact sedans to SUVs, and off-road trucks, rather than variations within a single design family, in an effort to effectively cover the space of designs.
2.3 Designing Large Physics Models for Aerodynamics
While data is essential for building pre-trained models, certain neural network architectures are particularly well-suited to steady-state aerodynamics and surrogate learning for partial differential equations (PDEs) with varying geometric boundary conditions. Because vehicle surface geometry is our primary input, we draw on geometric deep learning approaches (Bronstein et al., 2021), including learning on meshes, graphs, and point clouds. This problem setting also connects naturally to neural operators (Azizzadenesheli et al. 2024), which learn continuous function-to-function mappings governed by physical laws. Many architectures in both domains use attention mechanisms to capture dependencies between points, borrowing ideas from large language models. Two architectures that perform particularly well across multiple tasks are Point Cloud Transformer (Guo et al., 2021) and Transolver (Wu et al., 2024). We adapted both into neural operator formulations by incorporating cell areas and volumes. More broadly, the research community has proposed a wide range of architectures with strong performance in automotive aerodynamics, as evaluated in a recent benchmarking study by Elrefaie et al. (2025).
Beyond architecture, both the training paradigm and curriculum matter. While supervised learning dominates surrogate modeling, the space of possibilities is broad: one can pre-train on geometry before fine-tuning on physics, leverage multi-modal pre-trained models, use multi-fidelity or synthetic data, or explore in-context learning approaches. We have begun exploring some of these directions.
We optimized hyperparameters and developed efficient implementations that produce both physical fields and integrated scalar quantities using separate network heads. We focus on Transolver for the results below. PCT showed similar behavior, while Dora-VAE (Chen et al., 2025), a generative geometry model pre-trained on diverse shapes, had limited success in adapting to physics prediction.
Even highly accurate models can deviate from reality, which leads engineers to a critical question when making decisions: when can the model be trusted? For this reason, engineering models must be equipped with uncertainty quantification (UQ). All of our models support Monte Carlo Dropout inference with standard deviation scaling derived from post-training calibration, both of which are widely used and well-established UQ techniques. This produces uncertainty estimates across spatial field predictions that propagate naturally to downstream quantities.
As an illustrative example, integrating the predicted pressure field along the length of the vehicle yields a cumulative estimate of the drag coefficient. This representation highlights which regions of the vehicle geometry contribute most strongly to drag and presents credible intervals that enclose the ground-truth curve.
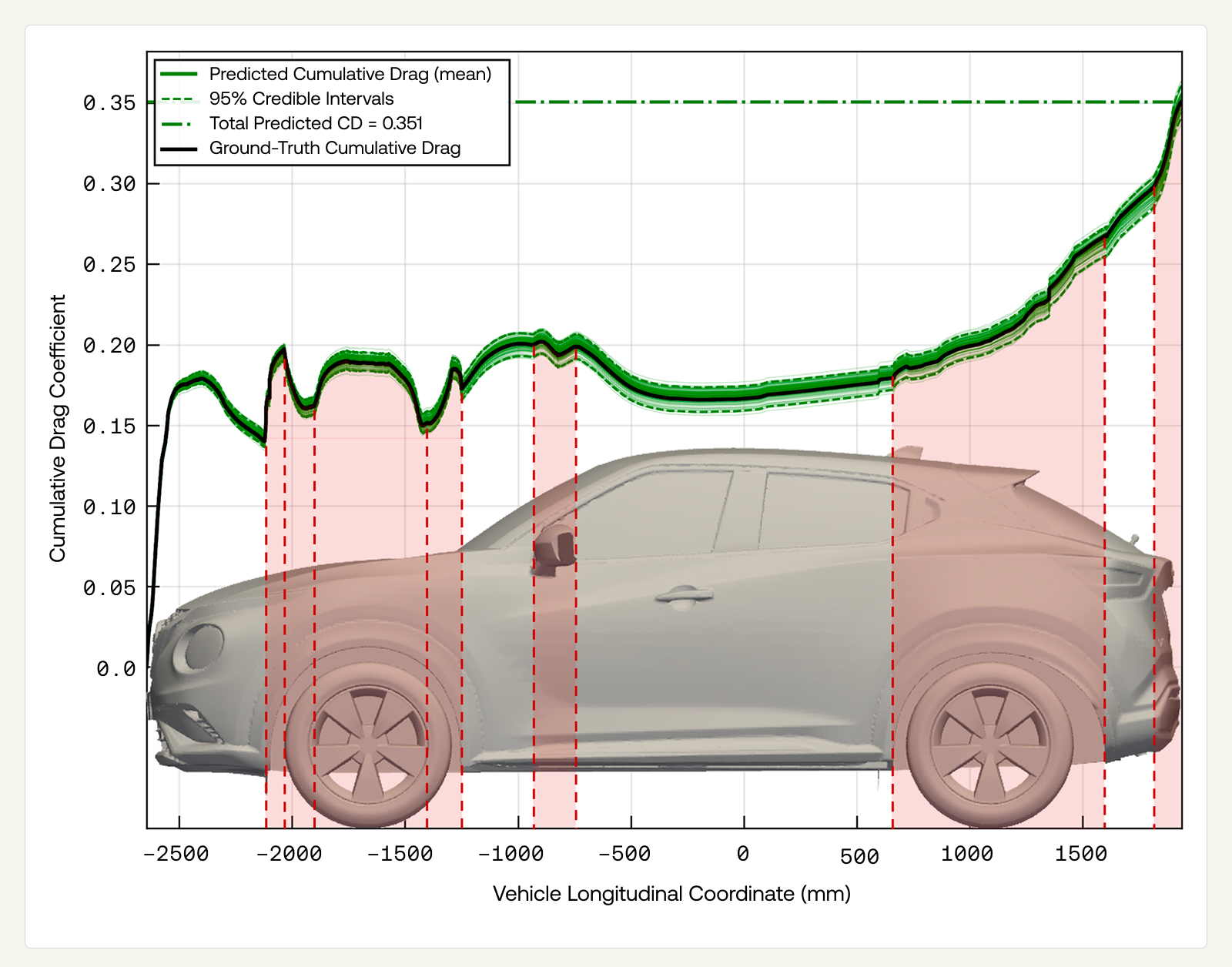
We reserve a deeper discussion on UQ for a future post, where we will show how accompanying model outputs with such information can drive key engineering outcomes and guide dataset expansion (e.g., by employing active learning).
3. Results
In the results below, we consider a Transolver-based architecture (PXTransolver) trained on different datasets and evaluated on tasks designed to distinguish between memorizing and generalizing physical behavior across geometric design and simulator settings. The model has ~28M parameters, a choice we will be revisiting in the future as our dataset expands. We first establish strong in-distribution baselines (Section 3.1), then evaluate generalization along two axes: across designs, using train and test splits without common baseline geometries (Section 3.2), and across simulators, using cross-dataset evaluation where training and test data come from different simulators (Section 3.3). Because the available datasets use non-overlapping designs and simulators, cross-dataset evaluation necessarily confounds both factors. Despite this complication, we attempted to understand the contribution of each factor to performance degradation and find both factors to be significant. Finally, we show that training on datasets from multiple simulator sources retains model performance across simulator settings, suggesting a viable path toward mitigation (Section 3.4).
Central to all experiments is how training and test sets are constructed. The official data split for DrivAerNet++ is based on random training and test partitions, allowing morphs derived from the same baseline geometries to appear in both sets. Because these morphs are highly similar, the resulting test samples effectively follow the same distribution as the training data. We refer to this evaluation setup as in-distribution (ID-design) splitting and construct analogous randomized splits for Luminary SHIFT-SUV and PXNetCar.
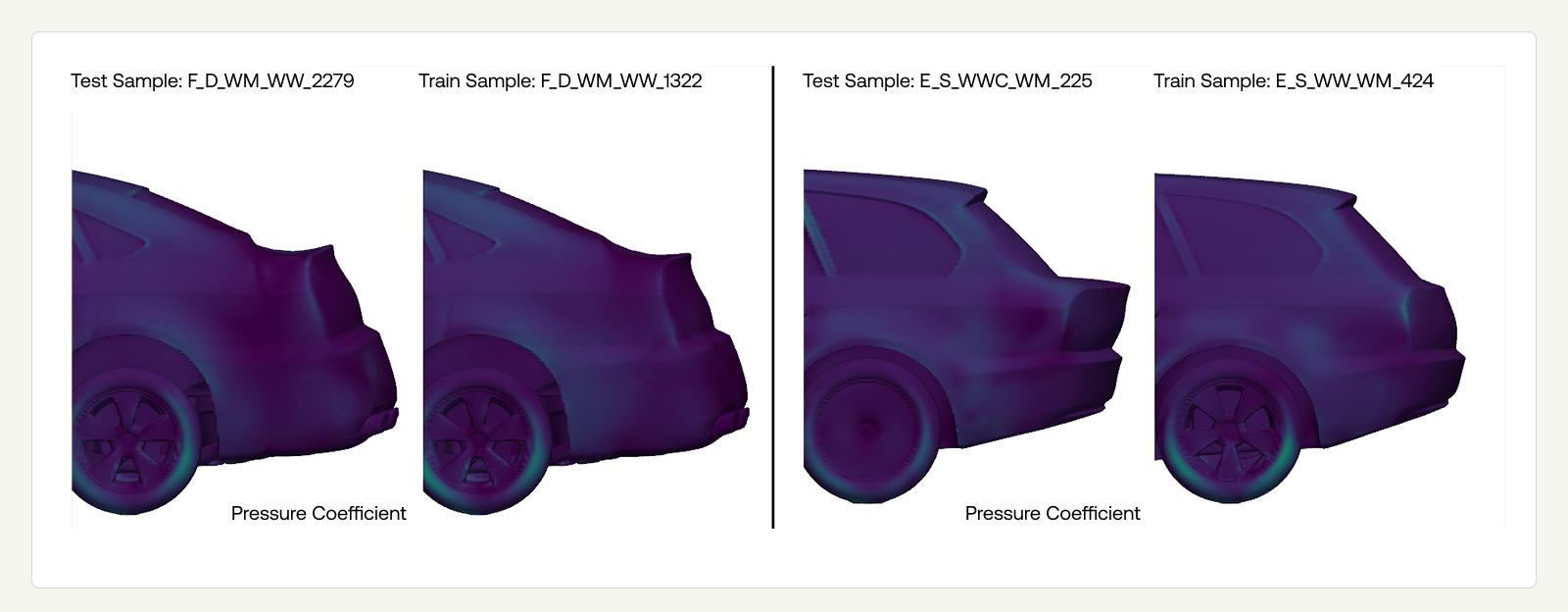
However, in-distribution (ID) performance is a poor proxy for real-world engineering capability, as novel customer designs often differ substantially from those seen during training. To illustrate the limitation of ID splits, we identified the most geometrically similar (Figure 4: left) and most geometrically distinct (Figure 4: right) pairs of morphed vehicles across the training-test split of DrivAerNet++. We found that even the most dissimilar morphs remain highly similar overall, with the global vehicle morphology largely unchanged and differences confined to relatively minor features.
To better reflect practical use, we define out-of-distribution (OOD-design) splits on DrivAerNet++, Luminary SHIFT-SUV, and PXNetCar, where morphs in different splits originate from distinct baseline geometries. Enforcing separation at the baseline level ensures that the test set meaningfully challenges the model to generalize to new design families, rather than to minor variations of familiar shapes.
Cross-dataset evaluation introduces a second generalization axis: the simulator. We refer to this as the OOD-sim task. Since the three datasets each use a different CFD code, evaluating a model trained on one dataset against another's test set confounds OOD-design with OOD-sim. We present zero-shot results quantifying this combined effect (Section 3.4), and a multi-dataset model that begins to disentangle the two factors (Section 3.5). Adaptation strategies such as fine-tuning on target simulator data and other techniques are underway and will be presented in future work.
We report model performance using established metrics: Relative $L^2$ (RL2) and mean absolute error (MAE) for field targets (surface pressure coefficient, wall shear stress coefficient, volume pressure coefficient, and normalized velocity), as well as MAE, Spearman's rank correlation coefficient (SR), and $R^2$ for scalar targets. Note that we do not use cubature weights in RL2, which appears standard in the literature. We also report the baseline-averaged SR where appropriate; this is a measure of how well the model ranks designs within each baseline family, which better reflects engineering practice.
Scalar drag and lift coefficients are predicted via an additional scalar head, while integrated drag and lift are obtained by integrating the pressure and wall shear stress coefficients. We omit lift coefficient performance in this blog for simplicity. Drag coefficient is particularly important for engineering applications — design optimization workflows depend on reliably ranking candidates according to performance objectives such as drag reduction.
We curate views for experimental results in the sections that follow to highlight particular aspects, but we give a comprehensive view that contains all performance metrics for all tasks (ID-sim ID-design, ID-sim OOD-design, and OOD-sim OOD-design) in the Appendix (Figure 11).
3.1 In-Distribution Performance
In our initial experiments, we evaluate our model using ID splits, where random train-test partitions allow morphs of the same baseline to appear in both sets. For DrivAerNet++, we use the publicly available split to enable direct comparison with previously published results. For Luminary SHIFT-SUV, we use 80/10/10 random splitting, as in Alkin et al. 2025b and Adams et al. 2025, and thus expect comparable results.
We report non-dimensional quantities, as is common in engineering. The metrics summarized in Table 1 show that the trained PXTransolver accurately predicts both local field quantities and global aerodynamic coefficients. On DrivAerNet++ and Luminary, we compare against results reported in the literature: AB-UPT (Alkin et al. 2025a, Alkin et al. 2025b), GAOT (Wen et al. 2025), TripNet (Chen et al. 2025), and GeoTransolver (Adams et al. 2025). We convert results from the literature using their reported freestream velocities ($30 \textnormal{m}/\textnormal{s}$ and $31.298 \textnormal{m}/\textnormal{s}$ for DrivAerNet++ and Luminary SHIFT-SUV, respectively) and air densities ($1.184 \textnormal{ kg}/\textnormal{m}^3$ and $1.204 \textnormal{ kg}/\textnormal{m}^3$ for DrivAerNet++ and Luminary SHIFT-SUV, respectively). For Luminary SHIFT-SUV, we averaged the two reported classes, Fastback and Estate, from Alkin et al. 2025, and Adams et al. 2025, to recover the across class test metrics.
A technical audit of the DrivAerNet++ dataset revealed two issues with the wall shear stress (WSS) vector. First, the WSS sign convention differs from that commonly used elsewhere, across all vehicles in the dataset. Second, for the estate and notchback vehicles that employed half-car symmetry, the already incorrectly signed WSS was further corrupted by an incorrect reflection through the symmetry plane during post-processing. We have not ablated the effect of these corrections on DrivAerNet++, nor have we re-trained the referenced models. Thus, WSS comparisons on DrivAerNet++ are not like-for-like: our model was trained on the corrected data, whereas the referenced models were trained on the uncorrected data.
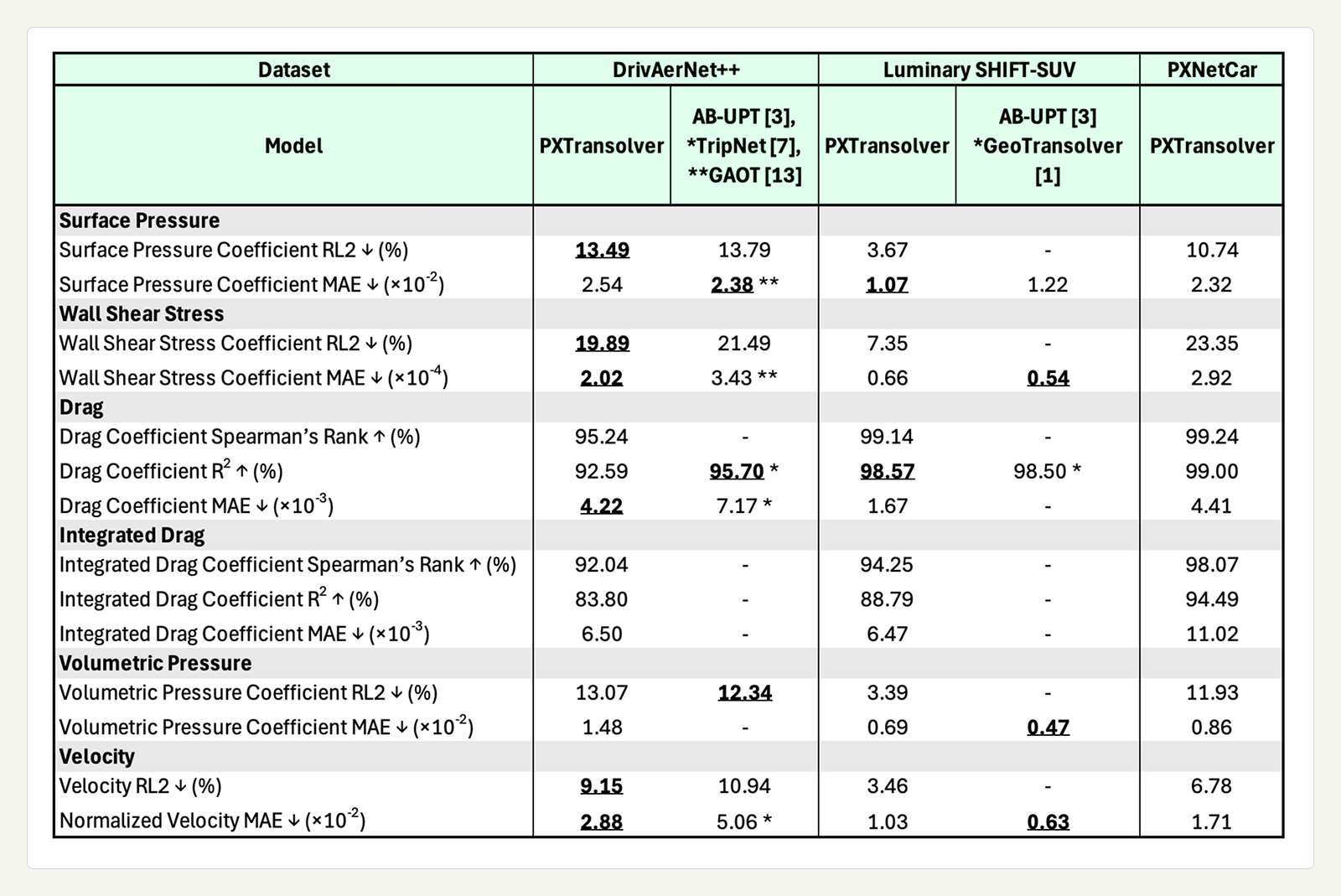
Across all three datasets, our results show strong ID performance. On DrivAerNet++ and Luminary SHIFT-SUV, PXTransolver achieves state-of-the-art surface pressure coefficient performance, and is competitive across other metrics with recently published results. Models trained on DrivAerNet++ and PXNetCar show similar performance, consistent with both using RANS simulations. The metrics on the Luminary SHIFT-SUV trained model are stronger than those on DrivAerNet++ and PXNetCar, which may reflect its lower design diversity, the use of higher-fidelity DES rather than RANS, or both.
WSS prediction remains challenging, as it shows notably weaker performance than pressure. WSS is more sensitive to local geometric features and mesh resolution, and may also vary more across simulators. Improving WSS prediction remains an active focus.
Integrated drag coefficients underperform relative to scalar head predictions. Improving this is an active research area for PhysicsX.
3.2 OOD-Design Performance
The true test of a pre-trained model is its ability to generalize beyond the training distribution. In this section, we evaluate OOD performance along the design axis by constructing OOD-design splits for each dataset, in which morphs in the training and test sets originate from entirely separate baseline geometries. This separation at the baseline level ensures that the test set presents genuinely novel design families, rather than minor variations of shapes already seen during training.
The specific splits are as follows:
- For Luminary SHIFT-SUV, which consists of two baselines, the training set consists of Estate vehicles (N=898), with an ID test set of 100 Estate samples and an OOD-design test set of 995 Fastback samples.
- For DrivAerNet++, which consists of three baselines, the training set includes Notchback and Fastback vehicles (N=6,059), with an ID test set of 674 Notchback and Fastback samples and an OOD-design test set of 1,385 Estate samples.
- For PXNetCar, the training set spans 248 baseline designs and their morphs (N=18,804). The ID test set contains 470 samples from 47 baselines in the training set (10 samples per baseline, all morphs of each other). The OOD-design test set contains 1,212 samples from 12 held-out baselines (101 samples per baseline, all morphs of each other). Note that the training sets differ from those used in Table 1, as some baselines were held out for the OOD test set.
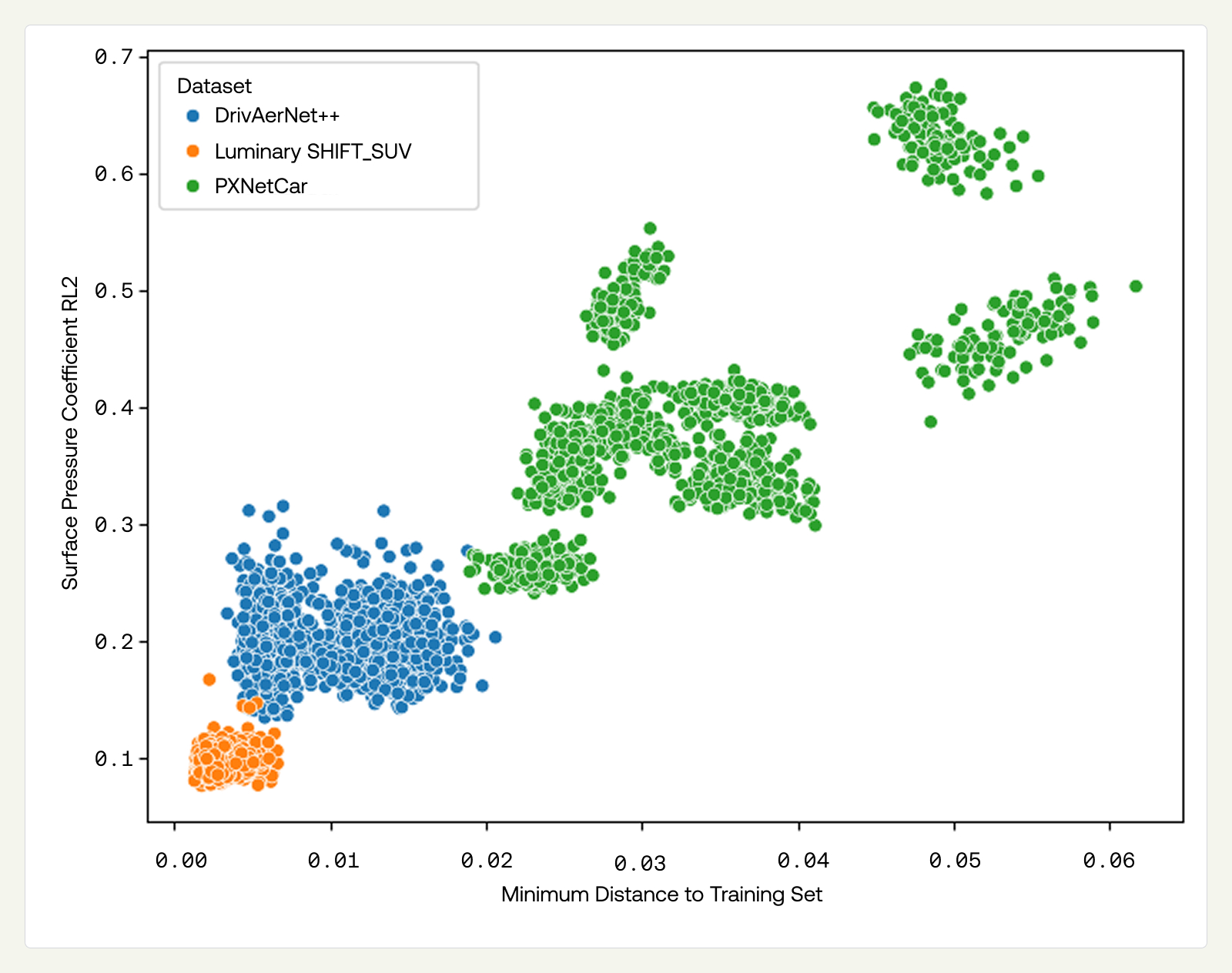
We first quantify how far the test splits are from each training set by computing the geometric distance between each sample in the test set and the nearest sample in the training set.
The OOD task difficulty increases from Luminary to DrivAerNet++ to PXNetCar, reflecting the greater geometric diversity of PXNetCar's held-out baselines. Notably, the Luminary OOD Fastback test set is not geometrically farther from the training set than the ID set under this metric. Restricting to Fastbacks with morphs distinct from the Estate training set (N=100) produces a clearer geometric separation between ID and OOD, but does not substantially change the OOD performance metrics reported below.
Table 2 shows the ID-design and OOD-design performance for PXTransolver trained on the three different datasets.
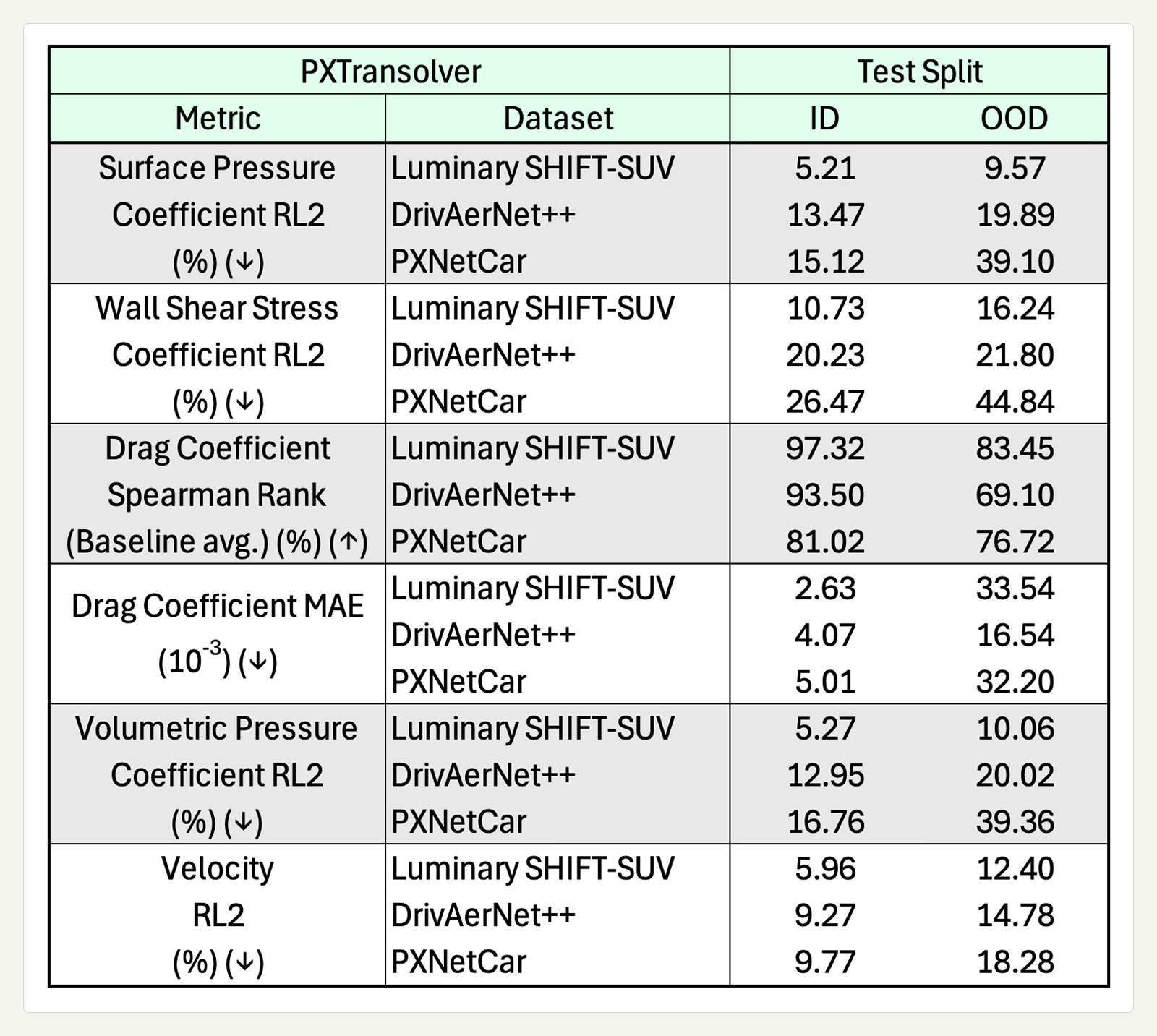
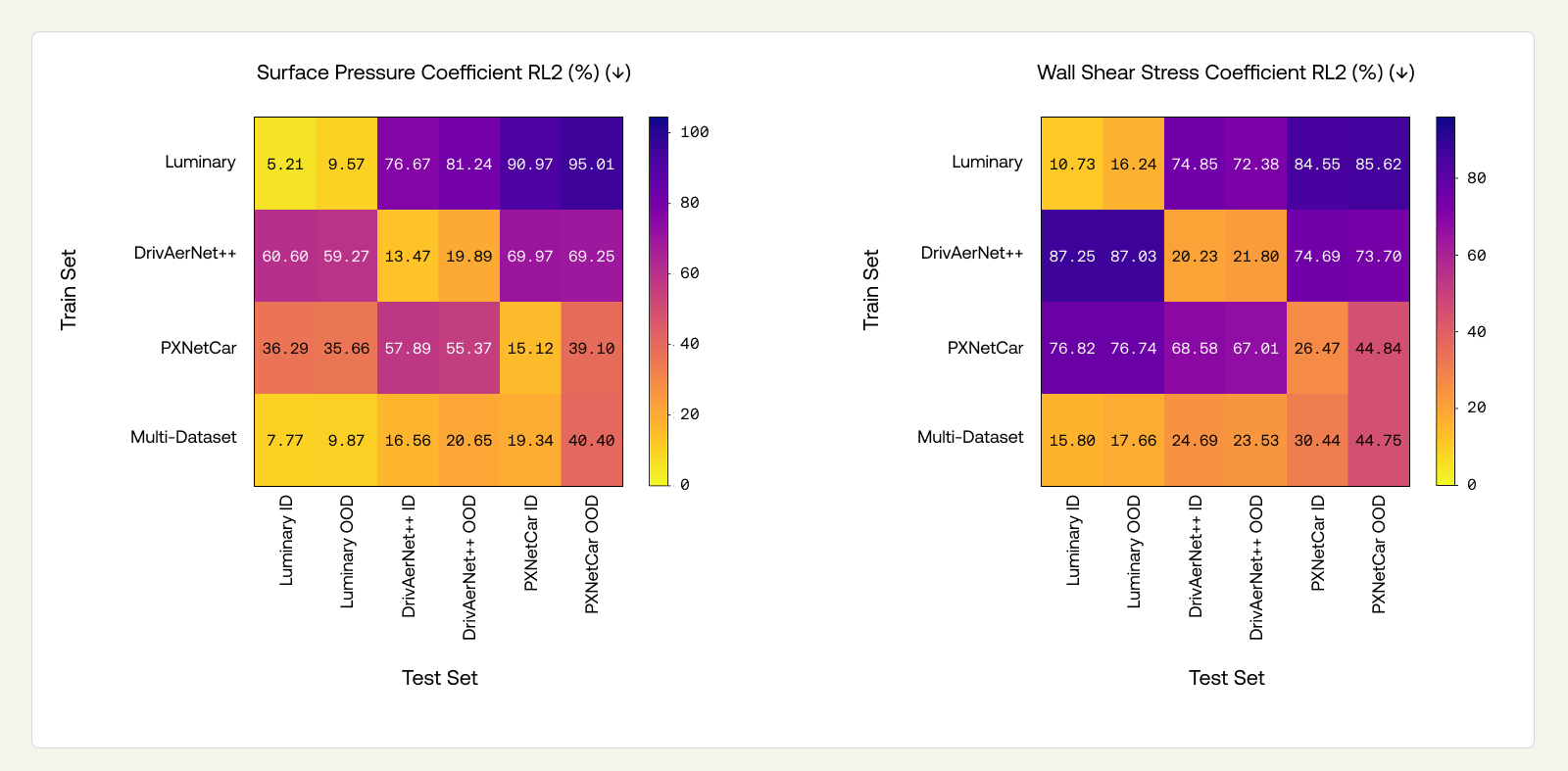
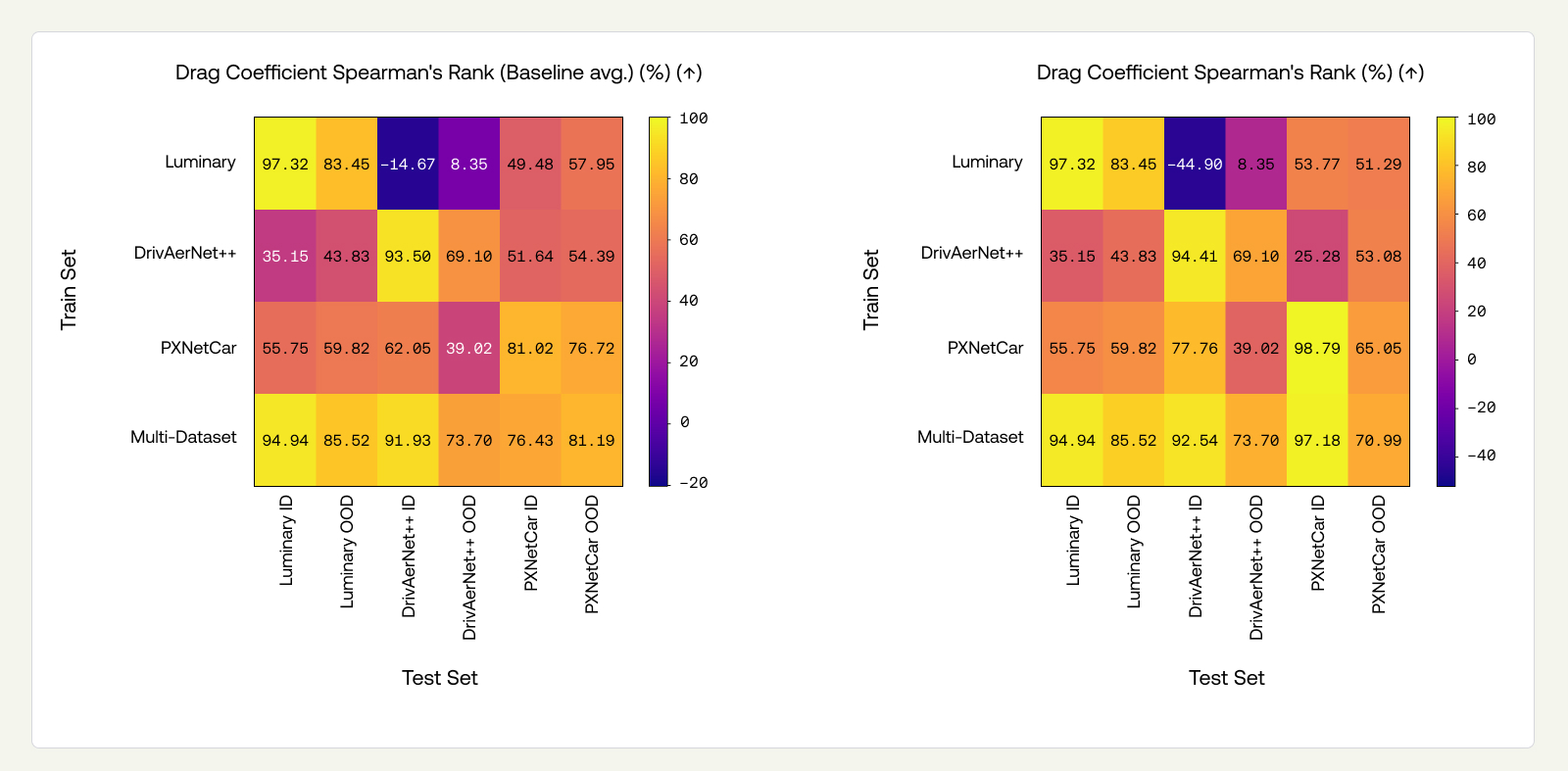
Single-dataset models perform well in-distribution but degrade substantially out-of-distribution. The degradation is consistent across all models, each trained on a dataset created with different simulators. For surface pressure RL2, the degradation is moderate on Luminary (5.21→9.57%) and DrivAerNet++ (13.47→19.89%), but severe on PXNetCar (15.12→39.10%). Drag coefficient Spearman’s rank tells a similar story: Luminary drops from 97.32% to 83.45%, DrivAerNet++ from 93.50% to 69.10%, and PXNetCar from 81.02% to 76.72%. PXNetCar represents a tougher OOD-design benchmark, better reflecting industrial use cases, since the dataset is inherently more diverse, as referenced earlier. Therefore, the OOD-design splits contain more instances and are more diverse than OOD-design splits for narrower datasets (DrivAerNet++, Luminary SHIFT-SUV). We attribute the observed gap in performance between Luminary ID and OOD, despite similar minimum chamfer distances, to limitations of the chamfer metric to capture all design variations that influence aerodynamic behavior.
We further examine how error varies with geometric distance to the nearest training sample in Figure 6, showing that errors are largely driven by this distance. Luminary's OOD samples cluster near the training set with low errors; DrivAerNet++'s are farther out with moderate errors, and PXNetCar's span the largest distances with the highest errors.
Our goal is for the model to be sufficiently accurate to replace numerical simulations within the design iteration loop, enabling designers to explore concepts independently and significantly accelerating their workflows. This requires models to perform well when applied to novel designs, a requirement not well-supported by publicly available datasets due to their low diversity. While zero-shot represents an ideal setting we strive for, we see great potential in employing pre-trained LPMs under a few-shot learning paradigm. We will be examining performance in such settings in future work, including via fine-tuning methods, and we expect performance in few-shot and zero-shot to be correlated.
3.2.1 OOD-Design Performance Scales with Dataset Size
We analyze how model performance improves as the training corpus is expanded by adding additional vehicles from the Data Factory. First, we define a diverse zero-shot test set of 1,672 samples, comprising 55 baselines of approximately 30 morphs each, on baselines that are never used during training. The number of baselines ensures diversity, while holding out entire baselines ensures the evaluation is genuinely OOD.
To build the training sets, we sample a fixed number of baselines from the remaining pool and include all associated morphs. As the number of sampled baselines increases, both the diversity of base designs and the total number of training samples grow accordingly, mirroring how new baselines are introduced and morphed in bulk within the Data Factory. Each training set is constructed from a different random selection of baselines. We train PXTransolver on each training subset, targeting only surface fields and forces, and evaluate it zero-shot on the fixed OOD test set. This random sampling procedure is repeated ten times for each training set size, and the standard error is reported to capture variability across runs.
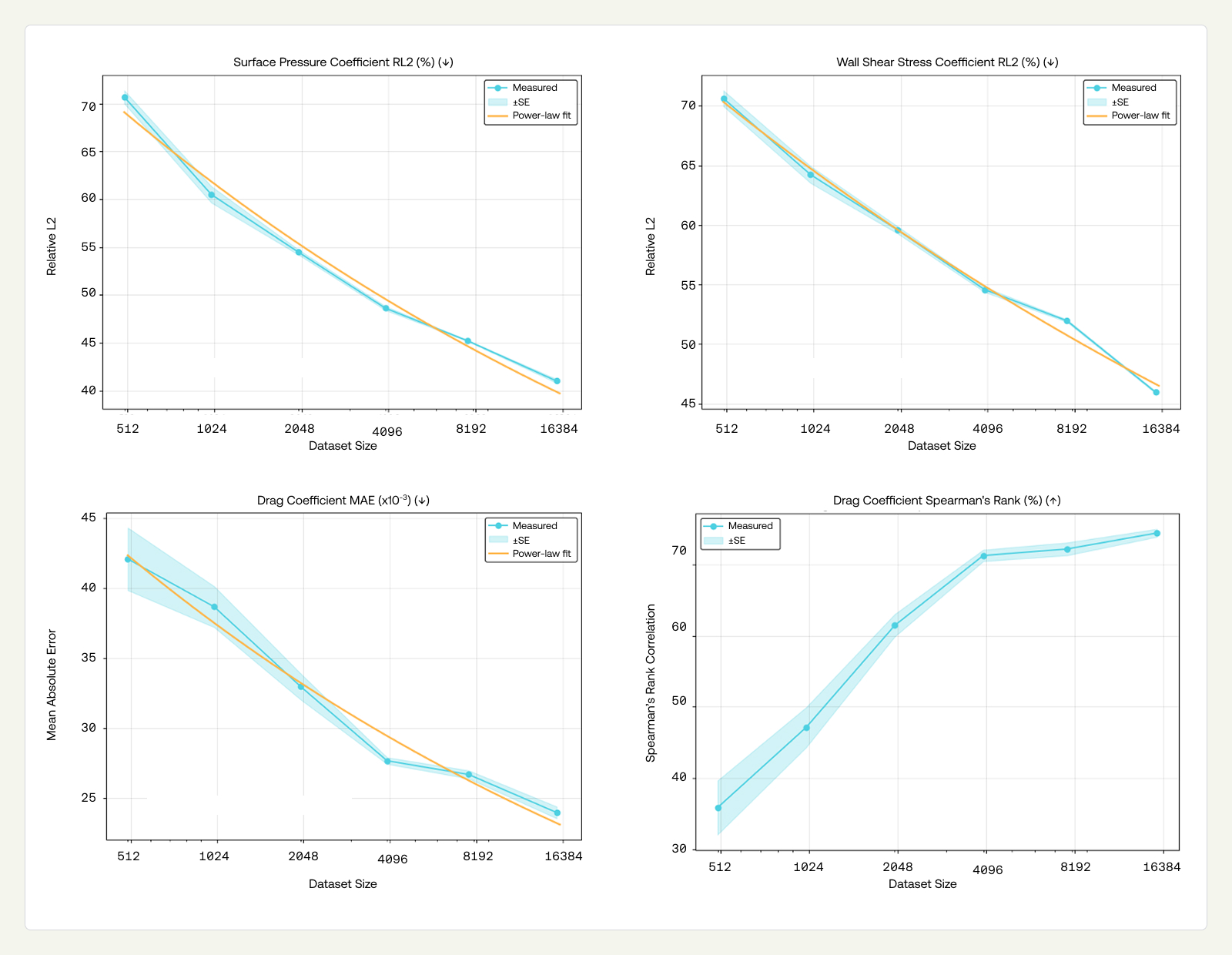
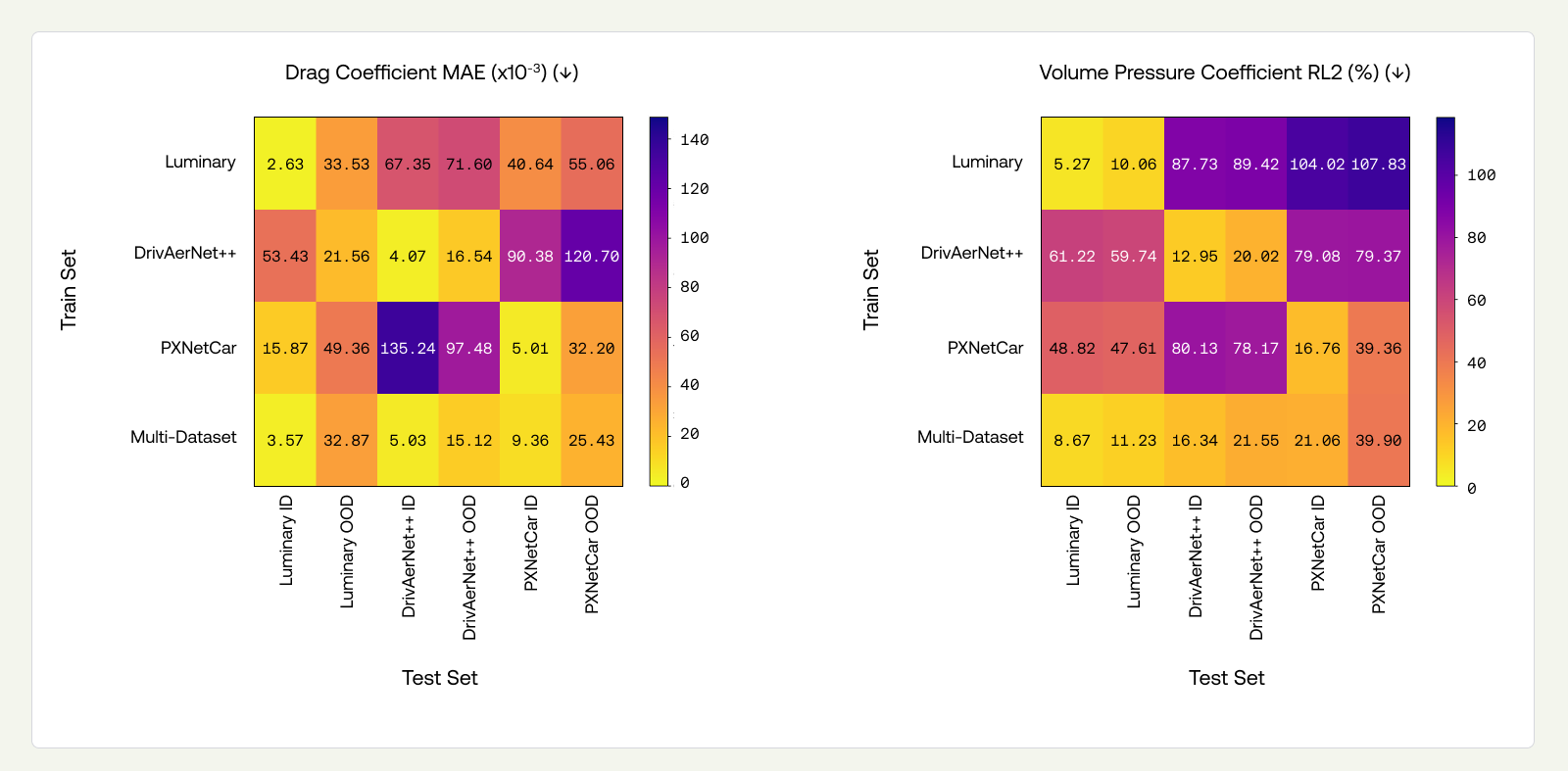
The data-scaling experiments demonstrate consistent improvement in OOD-design performance as training set size increases from 500 to approximately 16,000 samples. We fit power-law curves to the observed trends, obtaining exponents of β ≈ 0.168 for pressure, β ≈ 0.115 for WSS, and β ≈ 0.183 for drag coefficient MAE. These exponents characterize how OOD error decreases with increased geometric diversity, holding architecture fixed. A complete scaling analysis would jointly vary model capacity and data under compute constraints; here, we focus on data scaling alone. The continual addition of diverse data drives steady improvements in the model’s generalization performance, reinforcing that a robust Data Factory is the foundation of any LPM intended for industrial deployment. We aim to improve the exponents of these scaling laws to reach a useful pre-trained model (e.g., ~0.005 MAE for the drag coefficient) at around 100K designs.
3.3 OOD-Simulation Performance
We now turn to generalization across simulator setups (OOD-sim). As noted above, the available datasets use non-overlapping designs and simulators, so cross-dataset evaluation necessarily confounds OOD-design and OOD-sim. The ideal evaluation framework would allow us to disambiguate OOD-design and OOD-sim. This can be achieved by simulating DrivAerNet++ and Luminary designs in our simulation setup, which we may investigate in future work.
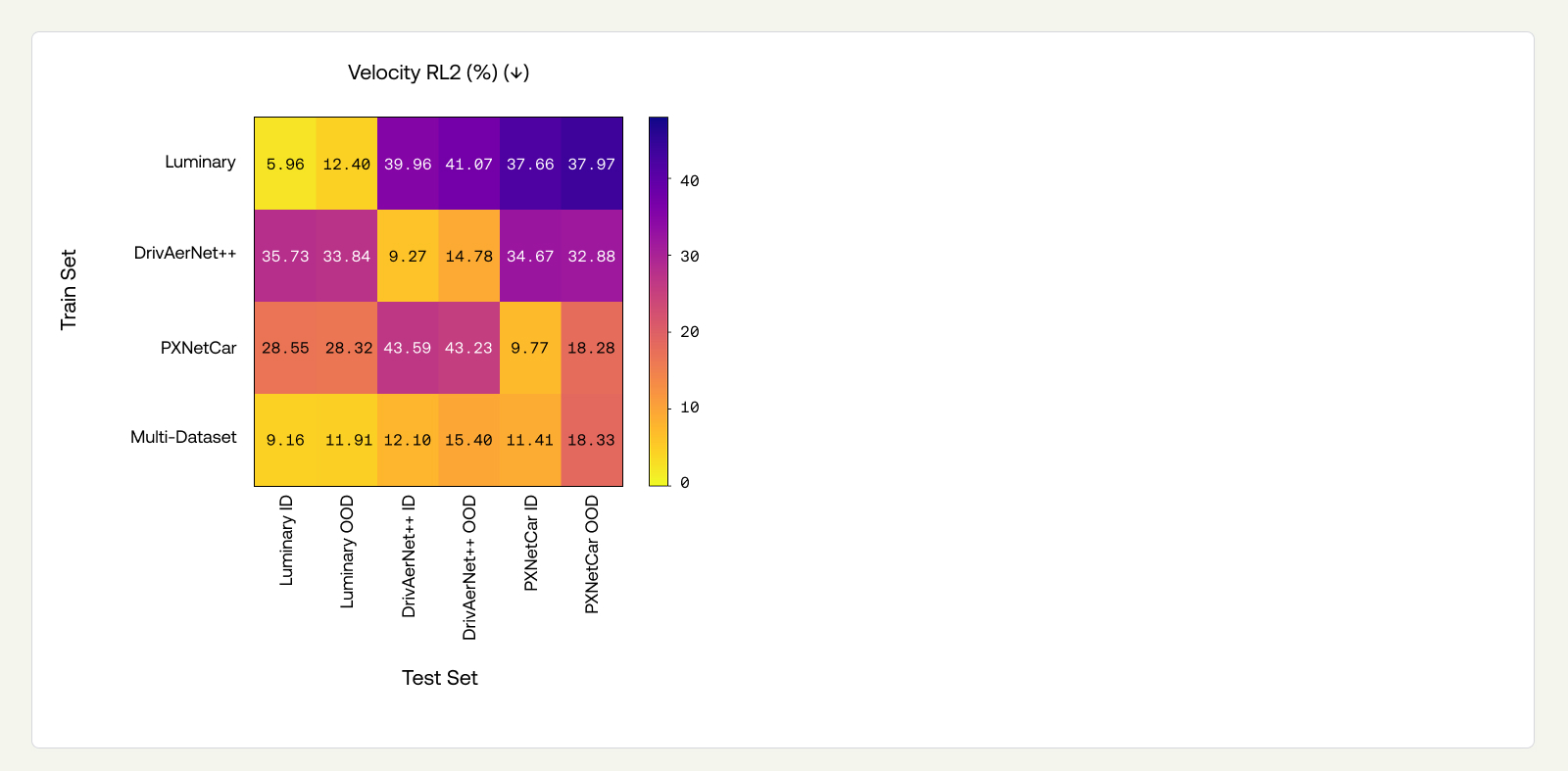
We tested the three PXTransolver models — trained on DrivAerNet++, Luminary SHIFT-SUV, and PXNetCar, respectively — on the OOD-design test sets of all three datasets. We present surface pressure coefficient RL2 and drag coefficient Spearman's rank results in matrices below, where diagonal entries represent OOD-design ID-sim performance (i.e., the same results as Section 3.2), and the off-diagonals represent OOD-design and OOD-sim jointly. A comprehensive view of all performance metrics on all splits can be found in the Appendix (Figure 11).
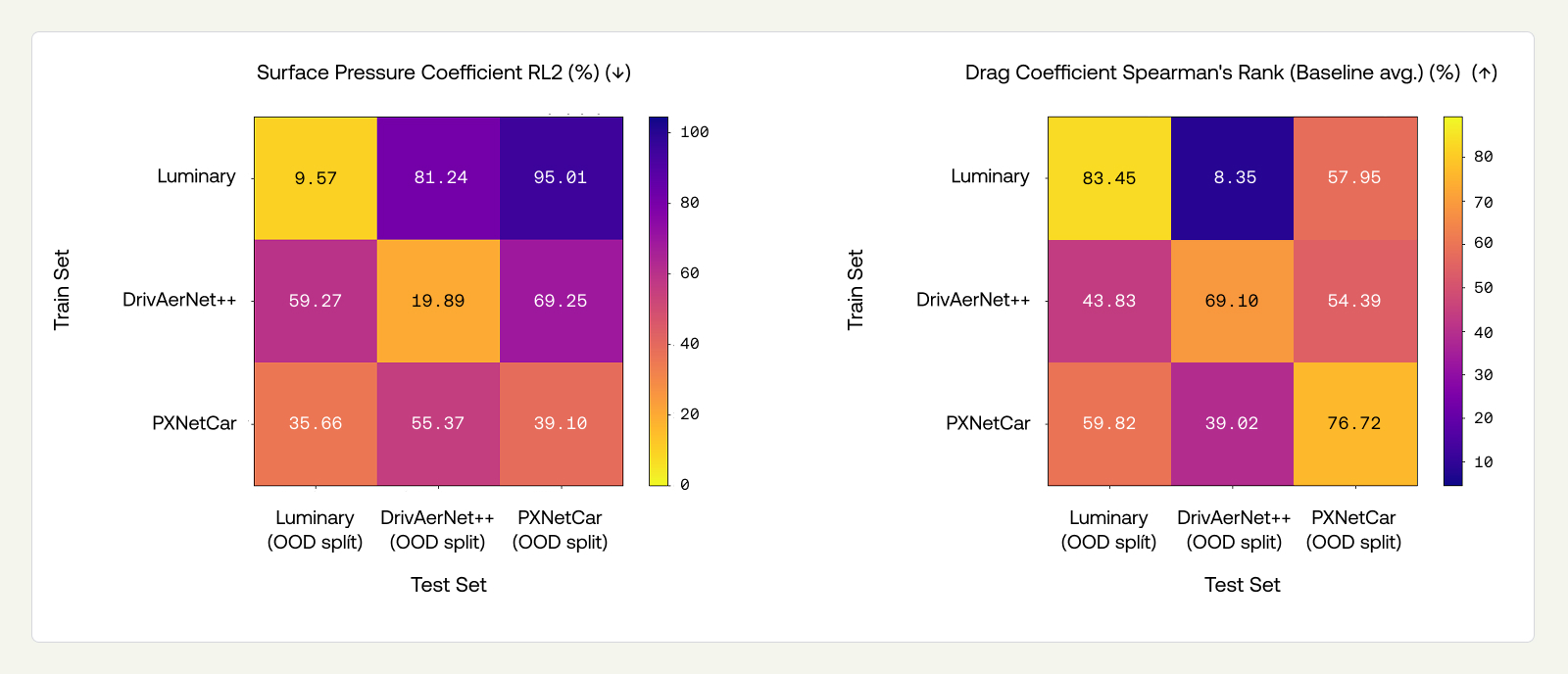
OOD-sim degrades performance substantially beyond OOD-design alone. Comparing the diagonals (OOD-design, ID-sim) to the off-diagonals (OOD-design, OOD-sim) reveals a large additional drop. For Luminary and DrivAerNet++, the degradation from switching the simulator is considerably larger than the degradation from ID-design to OOD-design reported in the previous section. For example, the Spearman’s rank for the Luminary model drops from 83.45% (OOD-design, ID-sim) to 8.35% on DrivAerNet++ and 57.95% on PXNetCar, compared to an ID to OOD-Design drop of roughly 14 percentage points. For PXNetCar, the pattern is less pronounced: its OOD-design task is already severe (recall that PXNetCar's held-out baselines are considerably more distant from the training set), which accounts for much of the degradation before simulator variation enters.
WSS is the quantity most sensitive to simulator differences. In Appendix (Figure 11), we see that WSS RL2 on off-diagonal entries ranges from 67% to 87%. This is consistent with WSS being strongly influenced by near-wall modeling choices that differ substantially across simulator codes and turbulence closures.
Taken together, these results confirm that OOD-sim is a critical challenge for pre-trained models, comparable to — and in many cases more difficult than — OOD-design generalization. They motivate the multi-dataset training approach we explore next.
3.4 Multi-Dataset Model
To explore whether simulator diversity in training can address the OOD-sim challenge identified above, we trained a single model on all three datasets (N=25,761), conditioning it on the dataset/simulator setting. We evaluate this multi-dataset model on the same ID-design and OOD-design splits used previously, and compare directly to the single-dataset models from Sections 3.2 and 3.4. As earlier, we present surface pressure coefficient RL2 and drag coefficient Spearman's rank results in matrices below, and provide a comprehensive view of all performance metrics on all splits can be found in the Appendix (Figure 11).
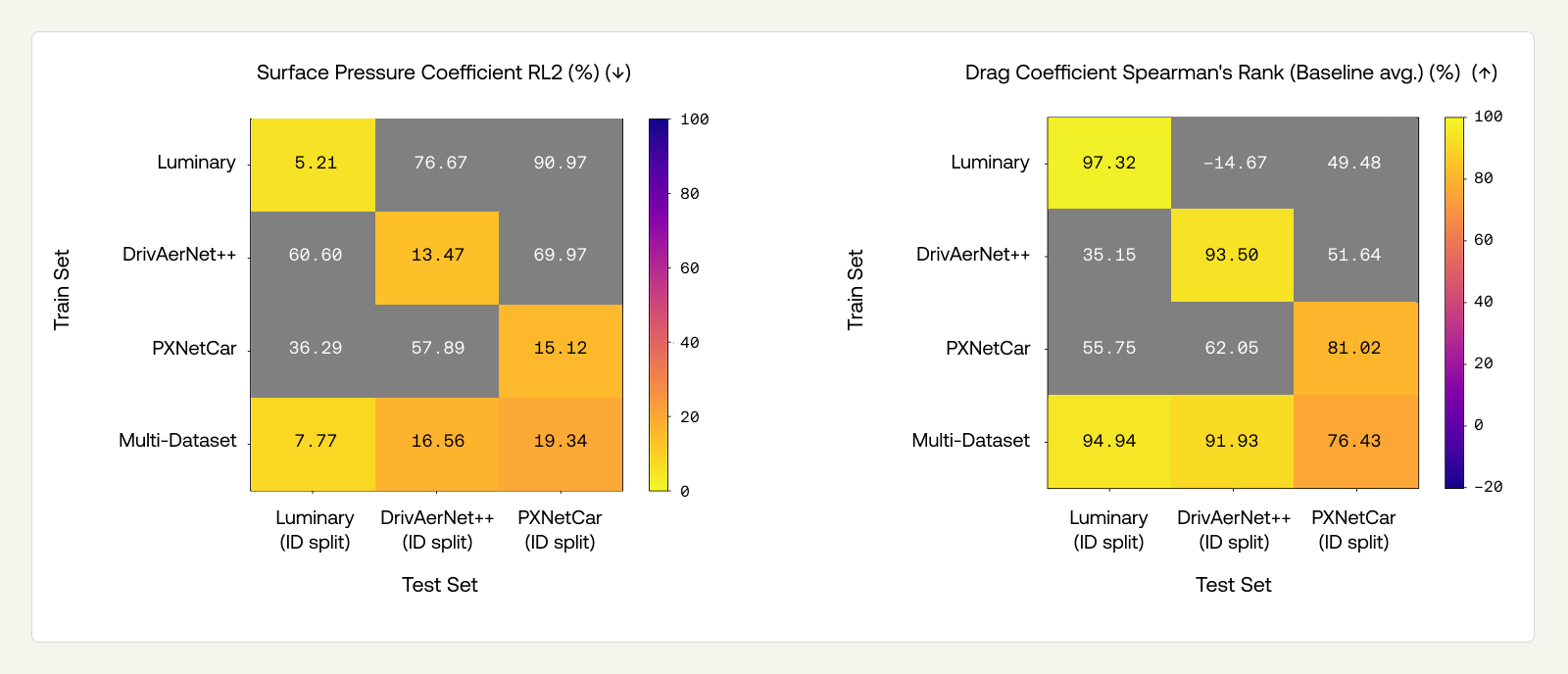
The ID-design cost is mild. Comparing the multi-dataset model to single-dataset diagonals on ID splits (Figure 9), there is a small drop in some metrics, concentrated in WSS and volumetric fields rather than in the quantities most critical for engineering workflows (drag ranking and surface pressure). The multi-dataset model achieves Spearman’s ranks of 94.94%, 91.93%, and 76.43% on the ID splits of Luminary, DrivAerNet++, and PXNetCar respectively, comparable to the single-dataset models.
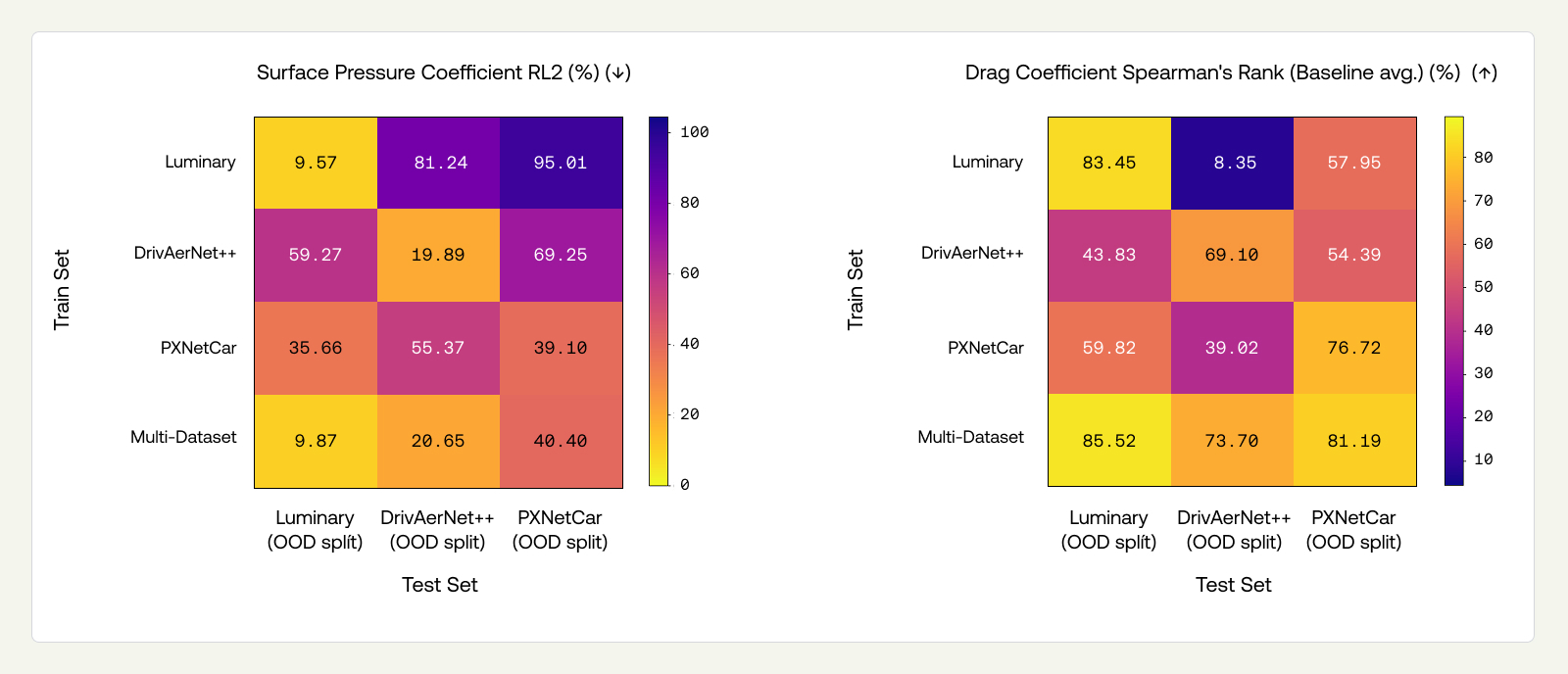
The multi-dataset model largely eliminates the OOD-sim penalty for simulators seen during training. The most striking result is the recovery of cross-simulator performance. In Section 3.4, single-dataset models suffer catastrophic degradation on other simulators' data: for example, the DrivAerNet++ and PXNetCar trained models incur a high RL2 error on surface pressure on Luminary’s OOD split (59.27% and 55.37%, respectively); and the Luminary trained model produces a near-random Spearman’s rank (8.35%) on the DrivAerNet++ OOD split. In contrast, the multi-dataset model achieves low RL2 error (9.87%) on Luminary’s OOD split and a high Spearman’s rank (73.70%) on DrivAerNet++’s OOD split, essentially reducing the problem to OOD-design alone. This pattern holds across metrics: what remains after multi-dataset training is predominantly design generalization error, not simulator generalization error.
OOD-design drag prediction improves. Beyond recovering OOD-sim, the multi-dataset model outperforms single-dataset models on drag metrics across their own OOD-design splits. Drag Spearman’s rank improves from 83.45→85.52% on Luminary, 69.1→73.7% on DrivAerNet++, and 76.72→81.19% on PXNetCar. Inspecting the Appendix (Figure 11), we see that drag MAE on PXNetCar drops from 0.0322 to 0.0254. Field-level metrics (surface pressure, WSS) show a small cost, consistent with the mild ID degradation noted above. The net effect is positive for engineering workflows, where reliable drag ranking is the primary objective.
These results highlight a path to useful models in industrial contexts. The multi-dataset model demonstrates that data from multiple simulators can be assimilated without compromising per-simulator performance, and with clear benefits for OOD-design generalization. However, we have not yet evaluated adaptation to a simulator unseen during training, which is the true test for industrial deployment. Expanding the diversity of simulators in PXNetCar is necessary but not sufficient: we cannot cover every simulator configuration in practice. The critical question is whether multi-simulator pre-training produces a stronger foundation for adaptation to novel settings with limited data, or whether fine-tuning a single-simulator model is equally effective. We are exploring this through adaptation strategies, including fine-tuning and in-context learning (where a small number of reference simulations are provided as context), and will present these results in a subsequent post.
4. Conclusion and the Road Ahead for Large Physics Models
Our work to date suggests that publicly available datasets used for pre-training are not sufficiently diverse to support the development of robust LPMs suitable for real-world applications, even within a relatively narrow vertical such as external automotive aerodynamics. This motivated us to build a Data Factory capable of generating representative CFD simulation data at scale, initially targeting design diversity, with plans to expand simulator coverage. Collecting, curating, and validating such data demands deep domain expertise to ensure the highest standards of quality.
On the modeling side, we demonstrate an architecture competitive with state-of-the-art models on established benchmarks in the literature (ID-design, ID-sim). Using PXNetCar alongside public datasets, we separate different aspects of benchmarking relevant to engineering practice (generalizing across designs vs across simulators) and demonstrate that prior work does not suitably address even out-of-distribution design evaluation, let alone generalization across simulators, which remains a hard and largely neglected task. Both OOD-design and OOD-sim tasks are most relevant for industrial applications, where the objective is to assess unseen geometries (OOD-design) in the context of established custom simulation workflows that may differ from ours (OOD-sim).
We validate previous findings of in-distribution performance, establish empirical data scaling laws for out-of-distribution design, and quantify degradation for out-of-distribution in simulator. A multi-dataset model conditioned on simulator settings recovers in-simulator performance and improves OOD-design drag prediction, though adaptation to unseen simulators remains an open challenge.
A number of directions follow from these findings. A major next step is to determine adaptation strategies (fine-tuning, in-context learning, meta-learning) that facilitate efficient generalization to customer data and simulator workflows. We will also present uncertainty quantification metrics and ablate modeling choices (capacity, architecture, data) as our dataset grows, to determine how best to assimilate increased diversity and volume. A key goal is to separate the OOD-sim and OOD-design tasks that are currently confounded by simulating the same car designs across multiple simulation methods. Finally, we will augment our dataset with varied simulation settings and boundary conditions (DES, other inlet velocities) and work towards a fully guided active learning pipeline to improve performance.
As we expand into new regimes and multi-physics scenarios, we are integrating these models directly into the PhysicsX platform, providing engineers with reliable access to a growing number of pre-trained LPMs and the workflows and capabilities built around them.
References
- Adams, C., Ranade, R., Cherukuri, R., & Choudhry, S. (2025). GeoTransolver: Learning Physics on Irregular Domains Using Multi-scale Geometry Aware Physics Attention Transformer. arXiv preprint arXiv:2512.20399.
- Alkin, B., Bleeker, M., Kurle, R., Kronlachner, T., Sonnleitner, R., Dorfer, M., & Brandstetter, J. (2025a). AB-UPT: Scaling neural CFD surrogates for high-fidelity automotive aerodynamics simulations via anchored-branched universal physics transformers. Transactions on Machine Learning Research.
- Alkin, B., Kurle, R., Serrano, L., Just, D., & Brandstetter, J. (2025b). AB-UPT for automotive and aerospace applications. arXiv preprint arXiv:2510.15808.
- Ashton, N.., Brandstetter, J.., & Mishra, S.. (2025). Fluid intelligence: A forward look on AI foundation models in computational fluid dynamics. arXiv preprint arXiv:2511.20455.
- Azizzadenesheli, K., Kovachki, N., Li, Z., Liu-Schiaffini, M., Kossaifi, J., & Anandkumar, A. (2024). Neural operators for accelerating scientific simulations and design. Nature Reviews Physics, 6(5), 320–328.
- Bronstein, M. M., Bruna, J., Cohen, T., & Veličković, P. (2021). Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv:2104.13478.
- Chen, Q., Elrefaie, M., Dai, A., & Ahmed, F. (2025). TripNet: Learning large-scale high-fidelity 3D car aerodynamics with triplane networks. CoRR, abs/2503.17400.
- Chen, R., Zhang, J., Liang, Y., Luo, G., Li, W., Liu, J., … Tan, P. (2025). Dora: Sampling and benchmarking for 3D shape variational auto-encoders. In Proceedings of the Computer Vision and Pattern Recognition Conference (pp. 16251–16261).
- Elrefaie, M.., Morar, F., Dai, A., & Ahmed, F.. (2024). DrivAerNet++: A large-scale multimodal car dataset with computational fluid dynamics simulations and deep learning benchmarks. Advances in Neural Information Processing Systems, 37, 499–536.
- Elrefaie, M., Shu, D., Klenk, M., & Ahmed, F. (2025). CarBench: A comprehensive benchmark for neural surrogates on high-fidelity 3D car aerodynamics. arXiv preprint arXiv:2512.07847.
- Guo, M. H., Cai, J. X., Liu, Z. N., Mu, T. J., Martin, R. R., & Hu, S. M. (2021). PCT: Point cloud transformer. Computational Visual Media, 7(2), 187–199.
- Luminary Cloud. (2025). Shift-SUV: High-fidelity computational fluid dynamics dataset for SUV external aerodynamics [Data set]. Hugging Face. https://huggingface.co/datasets/luminary-shift/SUV/
- Wen, S., Kumbhat, A., Lingsch, L., Mousavi, S., Zhao, Y., Chandrashekar, P., & Mishra, S. (2025). Geometry aware operator transformer as an efficient and accurate neural surrogate for PDEs on arbitrary domains. arXiv preprint arXiv:2505.18781.
- Wu, H., Luo, H., Wang, H., Wang, J., & Long, M. (2024). Transolver: A fast transformer solver for PDEs on general geometries. In International Conference on Machine Learning (pp. 53681–53705). PMLR.
Appendix: ID and OOD Performance Tables